検索条件
全4件
(1/1ページ)
a=21023の場合、a+bがオーバーフローしてしまう問題があります。
b=21023
a=2-1074のとき、a*0.5、b*0.5はともにアンダーフローで0になってしまい、結果も0になってしまいます。
b=2-1074
a=21023でオーバーフローしてしまいます。
b=-21023
a=5*2-1074としてみましょう。このとき、IEEE754の偶数丸めルールの関係で、
b=7*2-1074
a*0.5=2*2-1074となります。よって計算結果は7*2-1074となってしまい、真の6*2-1074になりません。
b*0.5=4*2-1074
a=(253-1)*2-1073とすると、
b=7*2-1074
(nearest)=2-1021+2-1073と値がずれてしまいます。a*0.5は無誤差ですが、b*0.5と加算で両方上向き丸めになった結果、真値(2-1021+2-1073+2-1075)を丸めたものとずれてしまいました。
(計算値)=2-1021+2-1072
midrad(I, m, r);とすると中心の近似mと、半径rを同時に計算します。これは、中心m、半径rの区間で I を包含する、すなわち、上端下端型の区間から中心半径型の区間への変換に使われることを意図しています。単純に
m = mid(I);とすれば良さそうなものですが、中心mに丸め誤差が入るので、これだと I を包含しない可能性があるのです。例えば、ε=2-52として、I=[1,1+3ε]とします。このとき、midとradを別々に計算すると、
r = rad(I);
m = 1+2εとなりますが、[m-r,m+r]は I を含まないことが分かります。midradを使うと、ちゃんと
r = 1.5ε
m = 1+2εになります。ミスが起こりやすいポイントなので気をつけて下さい。
r = 2ε
max([a,b],[c,d]) = [max(a,c),max(b,d)]のように行います。
min([a,b],[c,d]) = min(a,c),max(b.d)]
#include <kv/interval.hpp>
#include <kv/rdouble.hpp>
typedef kv::interval<double> itv;
using namespace std;
int main()
{
cout << max(itv(2., 4.), itv(3., 5.)) << endl;
cout << min(itv(3., 5.), itv(2., 4.)) << endl;
}
のようなプログラムを動かすと、予想に反して[2,4]という結果が帰って来ます。これは、std::max, std::minが呼び出されてしまっており、恐らくmaxは
[3,5]
template <class T>
T max(const T& a, const T& b)
{
return (a < b) ? b : a;
}
のような実装になっていて、[2,4]<[3,5]は偽なので[2,4]が返されてしまっていると推測されます。よく考えれば分かるとは言え、これは事故を誘発しやすいので、ちゃんと区間用のmaxとminを実装しました。kv-0.4.38で上のプログラムを動かすと、ちゃんと[3,5]となります。
[2,4]
#define NOMINMAX #include <windows.h>のようにwindows.hをincludeする前にNOMINMAXを定義して下さい。
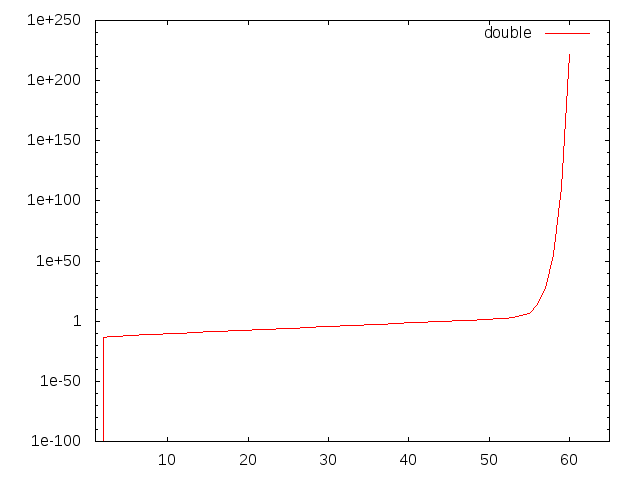
100 → (10回平方根) → 1.0045072 → (10回二乗) → 99.9806と、誤差が観測されました。更に回数を増やしてみると、
100 → (20回平方根) → 1.0000042 → (20回二乗) → 81.635475
100 → (25回平方根) → 1 → (25回二乗) → 1のようになりました。平方根を取った値は徐々に1に近づき、1+εのεを保持する桁数が徐々に小さくなっていって、誤差がひどくなっていく様子がよく分かります。
#include <iostream>
#include <cmath>
int main()
{
int i;
double x;
std::cout.precision(17);
x = 100;
for (i=0; i<10; i++) {
x = sqrt(x);
}
for (i=0; i<10; i++) {
x = x * x;
}
std::cout << x << "\n";
}
を実行すると、100.00000000000637のように誤差が入りました。kvライブラリを使って区間演算にしてみます。
#include <kv/interval.hpp>
#include <kv/rdouble.hpp>
typedef kv::interval<double> itv;
int main()
{
int i;
itv x;
std::cout.precision(17);
x = 100;
for (i=0; i<10; i++) {
x = sqrt(x);
}
for (i=0; i<10; i++) {
x = x * x;
}
std::cout << x << "\n";
}
すると、[99.99999999997776,100.00000000004346]のように100を含む区間が得られます。
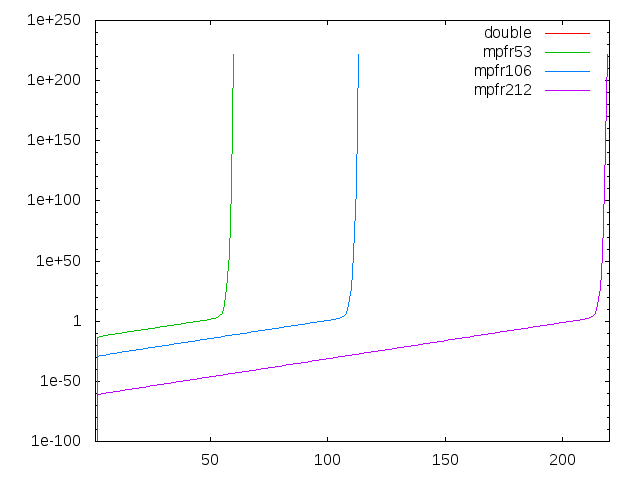
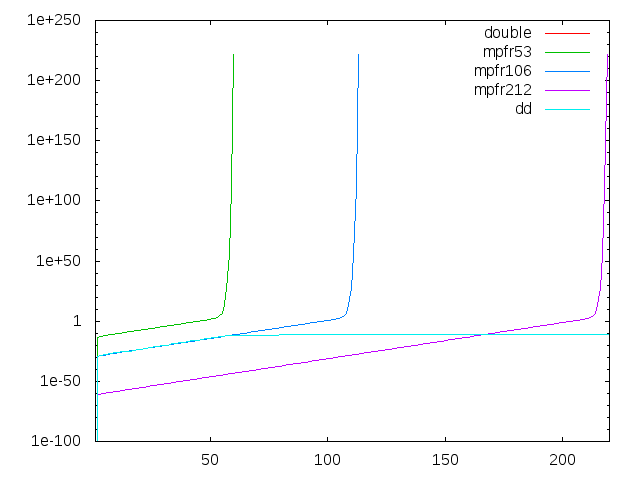
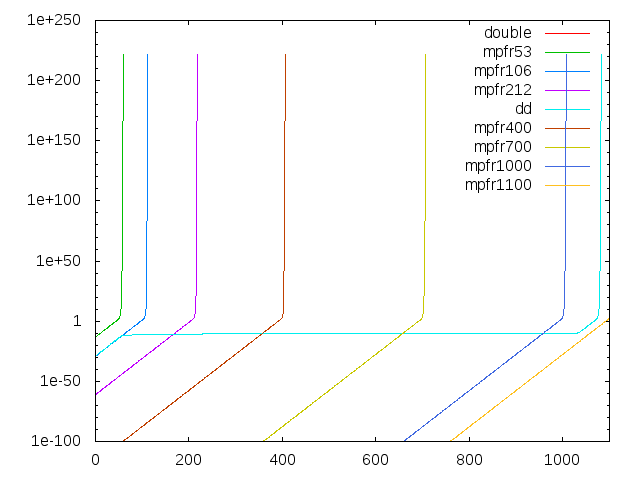
#include <kv/interval.hpp>
#include <kv/dd.hpp>
#include <kv/rdd.hpp>
typedef kv::interval< kv::dd > itv;
int main()
{
int i;
itv x;
std::cout.precision(17);
x = 100;
for (i=0; i<10; i++) {
x = sqrt(x);
}
for (i=0; i<10; i++) {
x = x * x;
}
std::cout << x << "\n";
}
のようなプログラムで区間幅を観察すれば容易に確かめられます。[1.000000000004188377884927590880100368969,1.000000000004188377884927590880168161704] (dd)ここではほぼ違いは見られません。上限と下限で一致している桁数は32桁で、4倍精度としては普通です。次に、平方根を80回にしてみます。
[1.000000000004188377884927590880118857896,1.000000000004188377884927590880168161704] (mpfr106)
[1.000000000000000000000003809307495356531,1.000000000000000000000003809307495356571] (dd)こちらは顕著な違いが見られます。mpfrの方は32桁で変わっていませんが、ddの方は38桁も一致していることが分かります。
[1.000000000000000000000003809307449647879,1.000000000000000000000003809307498951686] (mpfr106)
1.000000000004188427382700865564-4.9497773274684e-17ですが、80回のときは
1+3.8093074953565e-24で上位と下位が大きく離れています。たまたま収束先が1(=doubleで正確に表現可能)で、1+εのεの精密な表現力が問われるような問題だったので、ddが異常に高精度になったという仕掛けでした。