2024/02/07(水)g++-13と_Float64xとkv-0.4.56
今回は問題発生への対処です。ある人から、g++ version 13でkvがまったくコンパイルできない、clang++では問題ないと連絡が来ました。実際、ubuntu 23.10を入れて試してみると、test-rounding.ccとかtest-interval.ccみたいな基本的なプログラムすらコンパイルエラーになってしまいました。
調べてみると、_Float64x (IntelのFPUが持っている80bit拡張浮動小数点数) の関係する部分がエラーになっています。kvどころか、
#include <iostream>
int main()
{
_Float64x a;
std::cin >> a;
}
みたいな単純なプログラムがコンパイルエラーになってしまいます。また、
#include <iostream>
#include <limits>
int main()
{
std::cout << std::numeric_limits<_Float64x>::epsilon() << std::endl;
std::cout << std::numeric_limits<_Float64x>::max() << std::endl;
std::cout << std::numeric_limits<_Float64x>::min() << std::endl;
std::cout << std::numeric_limits<_Float64x>::infinity() << std::endl;
std::cout << std::numeric_limits<__float80>::epsilon() << std::endl;
std::cout << std::numeric_limits<__float80>::max() << std::endl;
std::cout << std::numeric_limits<__float80>::min() << std::endl;
std::cout << std::numeric_limits<__float80>::infinity() << std::endl;
std::cout << std::numeric_limits<long double>::epsilon() << std::endl;
std::cout << std::numeric_limits<long double>::max() << std::endl;
std::cout << std::numeric_limits<long double>::min() << std::endl;
std::cout << std::numeric_limits<long double>::infinity() << std::endl;
}
は、0 0 0 0 1.0842e-19 1.18973e+4932 3.3621e-4932 inf 1.0842e-19 1.18973e+4932 3.3621e-4932 infのように、numeric_limits<_Float64x>はすべて0を返してきます。
調べてみると、「_Float64xをサポートしているのはgccのみで、もともとg++では_Float64xをまったくサポートしていなかった。しかしversion 12までは単なるlong doubleのtypedefだったので、たまたまg++でも動いてしまっていた。最新のg++ version 13では_Float64xを部分的にサポートするようになったがlibstdc++はサポートしていない状態になり、結果的にまったく使えなくなってしまった」ということのようです。やりとりはこの辺。
gccのドキュメントの6.12 Additional Floating Typesでは、「As an extension, GNU C and GNU C++ support additional floating types, (中略) _float80 is available on the i386, x86_64, and IA-64 targets, and supports the 80-bit (XFmode) floating type. It is an alias for the type name _Float64x on these targets. 」とはっきり書いているので、g++でも_Float64xはサポートされているように見えるのですが。
IntelのCPUではlong double、__float80も_Float64xと同じ80bit拡張浮動小数点数です。こっちの2つはg++-13でも生き残っています。どちらかで全部書き換えることも考えたのですが、long doubleは異なるアーキテクチャだと異なる浮動小数点数フォーマットに対応していることが多く、トラブルを招く可能性が高い、__float80はgccのみのオリジナル拡張でclangで使えない、とそれぞれ問題があります。
もっともメジャーで、4月にはみんながubuntu 24.04を使い始めることを考えると、g++-13で動かないなんてのは使い物にならないも同然なので、緊急にkv-0.4.56をリリースしました。とりあえず最低限の変更で、g++-13では_Float64x関連の機能が全部働かないようにしました。g++-12以下ではすべて問題なく、g++-13では_Float64xを使う機能を除いてすべてコンパイルできるようになりました。他の変更は、ついでにoptimize.hppにちょっとした追加機能が入ったくらいです。
g++-14以降でちゃんと戻ることを祈るのみですが、こんなIntel CPUにしかない盲腸のような機能を使おうとするほうが悪い、という話でもあるのかな。
2022/09/16(金)kv-0.4.55
今年の1月に、M1 macの区間演算は遅い?という記事を書きました。このときに、ARM CPUでのinline assemblerによる丸めの向きの変更のコードを追加していたのですが、大して面白い変更では無かったので放置していました。気づいたら8ヶ月も経ってしまい、細かい修正も溜まってきたのでここでいったん公開することにしました。
というわけで、今回の変更はARM CPUで-DKV_FASTROUNDを付けるとinline assemblerによる丸めの向きの変更が使えるようになる、というものです。ARM 64bitだけでなく、一応ARM 32bitでも動くようにしたつもりですが、あまりテストされていません。
詳細は丸めモードの変え方とコンパイルオプションまとめの「6. ベンチマーク」に書きましたが、一般的にARM CPUでは丸めのモードを変更すると実行時間で大きなペナルティがあるようで、Intel CPUに比べてかなり遅いです。ARM CPUではハードウェアによる丸め変更を一切行わずにソフトウェアで方向付き丸めをエミュレートするのが一番速いという、残念な状況になっています。これを、精度保証に向かないCPUが普及しつつあって残念と見るか、エミュレーションのアルゴリズムを開発しておいて良かった、と見るか。
以下、とある区間演算を多用したプログラムを、端点がdouble精度の区間演算と、端点がdd精度の区間演算の場合について、オプションを変えながら実行したときの実行時間を上のページから抜き出しておきます。爆速のはずのM1 chipの計算速度が遅く、-DNOHWROUND (ソフトウェアエミュレートによる丸め変更) が一番まともになっているのが分かります。
core i5 11400
| 計算精度(端点の型) | コンパイルオプション (-O3 -DNDEBUGに加えて) |
計算時間 | |
|---|---|---|---|
| -DKV_USE_TPFMAなし | -DKV_USE_TPFMAあり | ||
| double | なし | 6.65 sec | |
| -DKV_FASTROUND | 3.74 sec | ||
| -DKV_NOHWROUND | 7.88 sec | 6.05 sec | |
| -DKV_USE_AVX512 -mavx512f | 2.74 sec | ||
| dd | なし | 37.20 sec | 33.58 sec |
| -DKV_FASTROUND | 25.08 sec | 21.52 sec | |
| -DKV_NOHWROUND | 92.24 sec | 71.81 sec | |
| -DKV_USE_AVX512 -mavx512f | 16.47 sec | ||
M1 MacBook Air
| 計算精度(端点の型) | コンパイルオプション (-O3 -DNDEBUGに加えて) |
計算時間 | |
|---|---|---|---|
| -DKV_USE_TPFMAなし | -DKV_USE_TPFMAあり | ||
| double | なし | 24.45 sec | |
| -DKV_FASTROUND | 22.36 sec | ||
| -DKV_NOHWROUND | 9.08 sec | 6.03 sec | |
| dd | なし | 108.8 sec | 100.6 sec |
| -DKV_FASTROUND | 102.4 sec | 94.64 sec | |
| -DKV_NOHWROUND | 84.60 sec | 53.76 sec | |
2022/01/13(木)M1 macの区間演算は遅い?
g++11 -O3 -I(kvのあるとこ) -I/opt/homebrew/include -L/opt/homebrew/lib hogehoge.cとかすれば動くようになりました。
で、なぜか区間演算が異常に遅いことに気付きました。とりあえず区間演算のベンチマークとして、
#include <iostream>
#include <kv/interval.hpp>
#include <kv/rdouble.hpp>
int main()
{
int i;
kv::interval<double> x;
x = 1;
for (i=0; i<1000000000; i++) {
x = (x*x-3)/(x+x);
}
std::cout << x << std::endl;
}
みたいなのを使います。加減乗除を一回ずつ含んでいて、[1,1]と[-1,-1]を交互に繰り返します。本当は変なベンチマークテストみたいにいろんな値を取る写像を使いたかったのですが、区間演算だとすぐに発散して[-∞, ∞]になってしまい、ベンチマークとしてふさわしくないものになってしまいました。これの実行時間を、ThinkPad X1 carbon (core i7 10510U, ubuntu 20.04, gcc 9.3)で計測すると、-O3で38.1秒程度でした。この状態では、丸めの向きの変更はfesetroundを使っています。kvライブラリには、Intelの64bit CPUのとき-DKV_FASTROUNDを付けるとfesetroundを使わずにSSE2の丸めの向きを制御するmxcsrレジスタに直接書き込むことによって高速化する機能があります。このときは、19.4秒と倍近くに高速化しました。更に、-DKV_NOHWROUNDを付けるとハードウェアによる丸めの向きの変更は一切行わず、twosumとtwoproductを用いて方向付き丸めのエミュレートを行わせることができます。このときは、35.7秒程度でした。
で、これをMacBook Air (M1, Monterey 12.1, gcc 11.2) で実行してみると、-O3でなんと142秒もかかってしまいました。fesetroundが重いのかと思い、aarch64なCPUに対しても-DKV_FASTROUNDが使えるようにkvを改造し(次期kv-0.4.55で入れる予定)実行してみると、114秒といくらか改善したものの、まだまだ遅いです。で、-DKV_NOHWROUNDだと、なんと23.8秒と劇的に改善しました。方向付き丸めのエミュレーションはかなり複雑な計算をしていて、こんなに速いはずはないのですが。まとめると、次のような感じです。
| -O3 | -O3 -DKV_FASTROUND | -O3 -DKV_NOHWROUUND | |
|---|---|---|---|
| X1 carbon | 38.1 | 19.4 | 35.7 |
| M1 MBA | 142 | 114 | 23.8 |
そこで、次のような実験をしてみました。変なベンチマークテストのベンチマークに毎回丸めの向きの変更を挿入してみます。fesetroundの実装に影響されないように、アセンブリ埋め込みの最速と思われる実装にします。
#include <stdio.h>
#include <stdint.h>
int main()
{
int i;
double x;
#ifdef __aarch64__
uint64_t reg;
uint64_t regs[4];
asm volatile ("mrs %0, fpcr" : "=r" (reg));
regs[0] = (reg & ~(3ULL << 22)) | (0ULL << 22); // nearest
regs[1] = (reg & ~(3ULL << 22)) | (2ULL << 22); // down
regs[2] = (reg & ~(3ULL << 22)) | (1ULL << 22); // up
regs[3] = (reg & ~(3ULL << 22)) | (3ULL << 22); // chop
#endif
#ifdef __x86_64__
uint32_t reg;
uint32_t regs[4];
asm volatile ("stmxcsr %0" : "=m" (reg));
regs[0] = (reg & ~(3UL << 13)) | (0UL << 13); // nearest
regs[1] = (reg & ~(3UL << 13)) | (1UL << 13); // down
regs[2] = (reg & ~(3UL << 13)) | (2UL << 13); // up
regs[3] = (reg & ~(3UL << 13)) | (3UL << 13); // chop
#endif
x = 0.5;
for (i=0; i< 1000000000; i++) {
#ifdef __aarch64__
#ifdef ROUND_CHANGE1
asm volatile ("msr fpcr, %0" : : "r" (regs[0]));
#endif
#ifdef ROUND_CHANGE2
asm volatile ("msr fpcr, %0" : : "r" (regs[i%4]));
#endif
#endif
#ifdef __x86_64__
#ifdef ROUND_CHANGE1
asm volatile ("ldmxcsr %0" : : "m" (regs[0]));
#endif
#ifdef ROUND_CHANGE2
asm volatile ("ldmxcsr %0" : : "m" (regs[i%4]));
#endif
#endif
x = 1 / (x * (x - 1)) + 4.6;
}
printf("%g\n", x);
}
埋め込んだ丸め変更命令に2種類あって、- -DROUND_CHANGE1 丸め変更命令を埋め込むが、丸めの向きはずっとnearest
- -DROUND_CHANGE2 丸めの向きをnearest->down->up->chopと周期的に変更
| -O3 | -O3 -DROUND_CHANGE1 | -O3 -DROUND_CHANGE2 | |
|---|---|---|---|
| X1 carbon | 6.43 | 6.44 | 6.53 |
| M1 MBA | 6.29 | 6.29 | 15.04 |
なお、これはaarch64なアーキテクチャ全般に見られる傾向かどうかが気になったので、3万円のchromebook (Lenovo IdeaPad Duet Chromebook, MediaTek Helio P60T) で試してみたら、
| -O3 | -O3 -DROUND_CHANGE1 | -O3 -DROUND_CHANGE2 | |
|---|---|---|---|
| IdeaPad Duet | 15.8 | 20.7 | 20.9 |
ARMでのベンチマーク追加 (2022/6/30追記)
- OCI (Oracle Cloud Infrastructure)のAlways Free ARMで提供されている、Ampere Altraプロセッサ。Ubuntu 20.04、gcc 9.4.0。
- Planexのスマートフォン、Gemini PDA (CPUはMediatek MT6797X Helio X27)にTermuxで入れたclang 14.0.1
| -O3 | -O3 -DROUND_CHANGE1 | -O3 -DROUND_CHANGE2 | |
|---|---|---|---|
| X1 carbon | 6.43 | 6.44 | 6.53 |
| M1 MBA | 6.29 | 6.29 | 15.04 |
| IdeaPad Duet | 15.8 | 20.7 | 20.9 |
| Ampere Altra | 6.69 | 6.69 | 9.70 |
| Gemini PDA | 19.7 | 23.0 | 28.8 |
なお、とある方から富岳のA64FXでのベンチマークを聞かせてもらったのですが、少し異常な感じの結果(とても遅い)だったので何か測定ミスの可能性もあり、ここへの掲載はとりあえず控えます。
2022/01/06(木)kv-0.4.54
Intel 80bit浮動小数点演算器の活用
1つ目は、Intelの80bit浮動小数点演算器の活用です。IntelのCPUの浮動小数点演算は32bit時代までは主にFPUで、64bit時代からはSSE2で行われ、現在ではハードウェアとしてのFPUは使われずに眠っている、盲腸のような存在です。FPUは、IEEE754よりも高精度な、全長80bit、指数部15bit、仮数部64bitの浮動小数点演算器を持っていて、それゆえIEEE754に完全に従わせるのが難しく、いろいろトラブルも起こしてきました。せっかく眠っているハードウェアを、逆にちょっと高精度な演算器として活用しようというのが、今回の話題です。FPUの80bit演算は、長らくlong doubleという名前で使われることが多く、gcc/clangでは今でもその名前で使用することができますが、MSVCでは64bitのただのdoubleと同じ、他のアーキテクチャでは128bit floatだったりと、混乱を極めています。kvでは、最近規格化された、_Float64xという名前で80bit演算を行うことにしました。中田真秀先生もこの名前を推奨しています。
kvのintervalは、元々端点の型を自由にすげ替えられるように設計されていて、double, dd, mpfrを使うことができました。kv/rfloat64x.hppというファイルを作り、interval.hppの後にこれをincludeすることによって、interval<_Float64x>で区間演算を可能にしました。
次に、ちょうどdoubleを2つくっつけてdd型を作ったように、_Float64xを2つくっつけて、全長160bit、仮数部15bit、指数部128bit相当の、ddxという型を作りました。ddx.hppをincludeすると使うことができます。
更に、rddx.hppというファイルを作って、これをinterval.hppの後にincludeすることによって、ddx型を端点に持つような区間演算も行えるようにしました。
従来は、ddの指数部11bit、仮数部106bit相当で足りなければmpfrに頼るしか無かったのですが、ddxを使えば少しだけ粘ることができます。計算速度はddの1~2割増程度なので、まあまあ使えるかと思います。
i386 CPUの扱いの変更
今更サポートする意味は薄いですが、Intel CPUの32bit環境の扱いを変更しました。kvの機能のうち- double-double演算 (dd)
- -DKV_NOHWROUNDを付けたときの、CPUによる丸めの向きの変更を一切使わない丸めエミュレーション
そこで、float.hもしくはcfloatをincludeした後、FLT_EVAL_METHODマクロを調べ、これが0でなければddまたは-DKV_NOHWROUUNDを使ったプログラムはコンパイルできないようにしました。これが0であれば、数値の演算器上の長さとメモリ上の長さが一致します。Intelの32bit環境の場合そのままではコンパイルできず、-msse2 -mfpmath=sseとオプションを付けるなどしてSSE2を強制的に使わせるようにすればコンパイルできるようになります。FLT_EVAL_METHODが定義されない環境、あるいはSSE2を持たないIntel CPUは、古すぎるのでサポート外としました。
内部型の異なる区間同士の変換
内部型の異なる区間同士の変換に詳しく書きました。従来は、例えばmpfr型の区間xをdd型の区間yに代入するときは、
impfrtoidd(x, y);
のようにしなければいけなかったのが、単に
y = x;
と書けるようになりました。2021/12/23(木)変なベンチマークテスト
変なベンチマーク?
元々のきっかけは、のツイートでした。加減乗除が一回ずつ出てきて、発散やゼロ除算を起こさず無限に回れるループが面白いなと思いました。核心部は、
a = 123;
for (j = 0; j< 1000000000; j++) {
a = (a * a - a) / (a + a);
}
の部分です。確かに加減乗除を一回ずつ含んでいる。約分すると
a = (a - 1) /2
というループで、a=-1に収束します。ただ、初期値を-1にしたら最適化コンパイラに(ずっと-1であることを)見抜かれてしまってループを消されてしまったりしました。これに触発されて、値が一定でなく乱数のように振る舞い、最適化に消されず計算せざるを得ないような計算式はできないかなと考えてみました。
x = 0.5; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
初期値は0.4から0.6の間の適当な値にします。すると、0.4から0.6の間を乱数のように振る舞います。元の式は分母(a*a-a)と分子(a+a)が独立に計算できるのである種の並列性を活かすことができましたが、こちらは前の計算の結果が出てこないと次の計算が始められないような構造になっています。また、元の式はa*a-aの部分をFMAを使って計算して高速化できる可能性がありますが、こちらはFMAの使える箇所がありません。つまり、最新のCPUに備わっている高速化機構を拒否するような計算になっているので、純粋な(?)計算速度を計測できると思われます。このつぶやきに続けていくつかベンチマークを流しましたが、使ったプログラムや条件等、きちんと書き残しておこうと思って書いているのが、この記事です。
いろんな言語でベンチマーク
手元のマシンに入っていたいろんな言語で、手当たり次第ベンチマークをしてみました。すべてcore i7 9700、ubuntu 20.04です。すべて普通にaptで入ったバージョンのものを使用しています。なお、計算時間計測は短いものは数回動かして目視で平均的なものを採用、長いものは一発のみ、更にVMwareの中で動かしてるのであまり厳密なものではないことをご承知おきください。C++ (gcc)
#include <iostream>
int main()
{
int i;
double x;
x = 0.5; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
std::cout << x << std::endl;
}
$ c++ --version c++ (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0 Copyright (C) 2019 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $ c++ -O3 bench.cc $ time ./a.out 0.487308 real 0m6.065s user 0m5.964s sys 0m0.000s
C++ (clang)
$ clang++ --version clang version 10.0.0-4ubuntu1 Target: x86_64-pc-linux-gnu Thread model: posix InstalledDir: /usr/bin $ clang++ -O3 bench.cc $ time ./a.out 0.487308 real 0m5.964s user 0m5.859s sys 0m0.008s
Java
class bench {
public static void main(String[] args)
{
int i;
double x;
x = 0.5;
long startTime = System.nanoTime();
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
long endTime = System.nanoTime();
System.out.println(x);
System.out.println((endTime - startTime) / 1000000000.);
}
}
$ java --version openjdk 11.0.13 2021-10-19 OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04) OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing) $ javac bench.java $ java bench 0.48730753067792154 5.940579694
fortran
fortranのプログラム書いたの人生初なんだが、これでいいのかな。program bench implicit none double precision :: x integer :: i x = 0.5d0 do i=1,1000000000 x = 1 / (x * (x - 1)) + 4.6d0 end do print *, x end program bench
$ gfortran --version GNU Fortran (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0 Copyright (C) 2019 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $ gfortran -O3 bench.f90 $ time ./a.out 0.48730753067792154 real 0m6.154s user 0m6.045s sys 0m0.004s
nim
数日前からnimを勉強し始めました。var x = 0.5 for i in countup(1, 1000000000): x = 1 / (x * (x-1)) + 4.6 echo(x)
$ nim --version Nim Compiler Version 1.0.6 [Linux: amd64] Compiled at 2020-02-27 Copyright (c) 2006-2019 by Andreas Rumpf active boot switches: -d:release $ nim c -d:release bench.nim Hint: used config file '/etc/nim/nim.cfg' [Conf] Hint: system [Processing] Hint: widestrs [Processing] Hint: io [Processing] Hint: bench [Processing] CC: stdlib_formatfloat.nim CC: stdlib_io.nim CC: stdlib_system.nim CC: bench.nim Hint: [Link] Hint: operation successful (14486 lines compiled; 3.525 sec total; 15.961MiB pea kmem; Release Build) [SuccessX] $ time ./bench 0.4873075306779215 real 0m6.029s user 0m5.912s sys 0m0.000s
julia
インタプリタだけどJITで爆速なjulia。一回勉強しかけたけど、途中で忙しくなって忘れつつある。
function hoge(x)
for i=1:1000000000
x = 1 / (x * (x-1)) + 4.6
end
return x
end
@time print(hoge(0.5))
$ julia --version julia version 1.4.1 $ julia bench.jl 0.48730753067792154 6.103540 seconds (500.26 k allocations: 22.774 MiB)
python
大人気だけど遅いと言われるpython。実際遅い。import time def hoge(x, n): for i in range(n): x = 1 / (x * (x - 1)) + 4.6; return x; s = time.perf_counter() print(hoge(0.5, 1000000000)) e = time.perf_counter() print(e - s)
$ python --version Python 3.8.10 $ python bench.py 0.48730753067792154 75.22909699298907
python + numba
numbaを使ってJITしてみた。こういう簡単なプログラムだとちゃんと速くなる。from numba import jit import time @jit def hoge(x, n): for i in range(n): x = 1 / (x * (x - 1)) + 4.6; return x; s = time.perf_counter() print(hoge(0.5, 1000000000)) e = time.perf_counter() print(e - s)
$ python bench2.py 0.48730753067792154 6.189143533993047
perl
$x = 0.5;
for ($i = 0; $i < 1000000000; $i++) {
$x = 1 / ($x * ($x - 1)) + 4.6;
}
print $x;
$ perl --version This is perl 5, version 30, subversion 0 (v5.30.0) built for x86_64-linux-gnu-thread-multi (with 50 registered patches, see perl -V for more detail) Copyright 1987-2019, Larry Wall Perl may be copied only under the terms of either the Artistic License or the GNU General Public License, which may be found in the Perl 5 source kit. Complete documentation for Perl, including FAQ lists, should be found on this system using "man perl" or "perldoc perl". If you have access to the Internet, point your browser at http://www.perl.org/, the Perl Home Page. $ time perl bench.pl 0.487307530677922 real 1m26.594s user 1m25.330s sys 0m0.029s
ruby
x = 0.5 for i in 1..1000000000 x = 1 / (x * (x - 1)) + 4.6 end print x, "\n"
$ ruby --version ruby 2.7.0p0 (2019-12-25 revision 647ee6f091) [x86_64-linux-gnu] $ time ruby bench.rb 0.48730753067792154 real 1m13.829s user 1m12.629s sys 0m0.052s
lua
最小限の仕様でどこまでまともな言語にできるかを追求したような、地味に好きな言語。
x = 0.5
for i=1,1000000000 do
x = 1 / (x * (x - 1)) + 4.6
end
print(x)
$ lua -v Lua 5.3.3 Copyright (C) 1994-2016 Lua.org, PUC-Rio $ time lua bench.lua 0.48730753067792 real 0m36.561s user 0m36.033s sys 0m0.009s
luajit
luaにはluajitという高速実装がある。$ luajit -v LuaJIT 2.1.0-beta3 -- Copyright (C) 2005-2017 Mike Pall. http://luajit.org/ $ time luajit bench.lua 0.48730753067792 real 0m5.958s user 0m5.863s sys 0m0.001s
awk
BEGIN {
x = 0.5;
for (i=1; i<=1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
print x;
}
$ awk --version GNU Awk 5.0.1, API: 2.0 (GNU MPFR 4.0.2, GNU MP 6.2.0) Copyright (C) 1989, 1991-2019 Free Software Foundation. This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program. If not, see http://www.gnu.org/licenses/. $ time awk -f bench.awk 0.487308 real 1m37.501s user 1m35.837s sys 0m0.095s
php
<?php
$x = 0.5;
for ($i=1; $i<=1000000000; $i++) {
$x = 1/($x * ($x - 1)) + 4.6;
}
echo $x, "\n";
?>
$ php --version
PHP 7.4.3 (cli) (built: Oct 25 2021 18:20:54) ( NTS )
Copyright (c) The PHP Group
Zend Engine v3.4.0, Copyright (c) Zend Technologies
with Zend OPcache v7.4.3, Copyright (c), by Zend Technologies
$ time php bench.php
0.48730753067792
real 0m16.971s
user 0m16.491s
sys 0m0.048s
octave
いくらなんでも遅すぎ?1; function x = hoge(x) for i=1:1000000000 x = 1 / (x*(x-1)) +4.6; end end tic; x = hoge(0.5); toc x
$ octave --version GNU Octave, version 5.2.0 Copyright (C) 2020 John W. Eaton and others. This is free software; see the source code for copying conditions. There is ABSOLUTELY NO WARRANTY; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. Octave was configured for "x86_64-pc-linux-gnu". Additional information about Octave is available at https://www.octave.org. Please contribute if you find this software useful. For more information, visit https://www.octave.org/get-involved.html Read https://www.octave.org/bugs.html to learn how to submit bug reports. $ octave bench.m Elapsed time is 1434.74 seconds. x = 0.48731
いろんな言語でベンチマークまとめ
- IEEE754には従っているようで、試したすべての言語で同じ結果が得られた。
- コンパイラ言語、もしくはJITありのインタプリタは大体6秒前後。
- JITなしのインタプリタは千差万別。地味にphpが速い、次にlua、有名インタプリタ勢は大体1分強。octaveはなにかおかしい。
| 言語 | 計算時間(秒) |
|---|---|
| C++(gcc) | 5.964 |
| C++(clang) | 5.859 |
| Java | 5.941 |
| fortran | 6.045 |
| nim | 5.912 |
| julia | 6.103 |
| python | 75.23 |
| python+numba | 6.189 |
| perl | 85.33 |
| ruby | 72.63 |
| lua | 36.03 |
| luajit | 5.863 |
| awk | 95.84 |
| php | 16.49 |
| octave | 1435 |
倍精度以外で計算させてみる
今度は言語はC++(gcc)に固定し、計算精度を倍精度(double)から他のものに変えて計算時間を測ってみます。むしろこっちに興味がある人もいることでしょう。単精度(float)
倍精度と変わらないかとも思いましたが、少し速くなるようです。
#include <iostream>
int main()
{
int i;
float x;
x = 0.5f; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1.0f / (x * (x - 1.0f)) + 4.6f;
}
std::cout << x << std::endl;
}
$ c++ -O3 float32.cc $ time ./a.out 0.596567 real 0m5.460s user 0m5.371s sys 0m0.004s
Intelの80bit拡張倍精度
SSE等のSIMD命令が出てくる前のIntel CPUで主に使われていたFPUの演算器は、全長80bit、仮数部64bitの拡張倍精度を持っています。今どきのx86_64向けのバイナリーではFPUを使うことはなく、盲腸のような存在ですが、頑張って使おうと思えば使うことが出来ます。ただし、今のMSVCでは使うのは難しいです。詳細は省きますが、gccやclangでは使うことができて、math.hまたはcmathをincludeした上で_Float64xという型名で使うのが一番良さそうです。
#include <iostream>
#include <cmath>
int main()
{
int i;
_Float64x x;
x = 0.5; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
std::cout << x << std::endl;
}
$ c++ -O3 float64x.cc $ time ./a.out 0.447779 real 0m6.436s user 0m6.325s sys 0m0.008sこの並列性が生かせない特殊なベンチマークのためだとは思いますが、倍精度と遜色ない速度が出ているのは少し驚きです。
double-double (qdライブラリ)
倍精度浮動小数点数を2つ使って、擬似的に106bit相当の仮数部を持つ4倍精度数を作る方法があります。double-doubleとか、縮めてddとか呼ばれます。Baileyによるqdライブラリがよく知られています。qdは、倍精度を4つ使うquad-doubleと2つ使うdouble-doubleの演算ができますが、今回はdouble-doubleの方を試してみました。sudo apt install qd-devでインストールしたものを使いました。
#include <iostream>
#include <qd/qd_real.h>
int main()
{
unsigned int oldcw;
fpu_fix_start(&oldcw);
int i;
dd_real x;
x = 0.5;
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
std::cout << x << "\n";
fpu_fix_end(&oldcw);
}
$ c++ -O3 qd.cc -lqd $ time ./a.out 5.343242e-01 real 0m48.568s user 0m48.047s sys 0m0.008s
double-double (kvライブラリ)
私が作っている精度保証付き数値計算のためのライブラリkvにも、double-double数が実装されているので、その計算時間も計測してみました。
#include <kv/dd.hpp>
int main()
{
int i;
kv::dd x;
x = 0.5; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
std::cout << x << std::endl;
}
$ c++ -O3 dd.cc $ time ./a.out 0.599108 real 0m37.365s user 0m36.737s sys 0m0.012s $ c++ -O3 -DKV_USE_TPFMA dd.cc $ time ./a.out 0.599108 real 0m30.161s user 0m29.656s sys 0m0.009sFMA非使用とFMA使用の両方でコンパイルしてみました。どちらでもqdより速いのは意外だったけど、嬉しいですね!
float128
IEEE754-2008で規格化された、全長128bit、仮数部113bitの浮動小数点形式です。残念ながらハードウェアでサポートしているCPUはほとんどありません。gccではlibquadmathで実装されたソフトウェアエミュレーションを使うことができます。cout等を使って楽をしたかったので、このサンプルではboost::multiprecisionを通じて使用しています。
#include <iostream>
#include <boost/multiprecision/float128.hpp>
int main()
{
int i;
boost::multiprecision::float128 x;
x = 0.5; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
std::cout << x << std::endl;
}
$ c++ -O3 float128.cc -lquadmath $ time ./a.out 0.547514 real 1m41.450s user 1m39.683s sys 0m0.028sソフトウェアエミュレーションにしては速い印象です。よほどすごい人が書いたのでしょうか。
mpfr
mpfrは有名なライブラリで、任意の仮数部長の浮動小数点演算を行うことができます。kvライブラリのmpfrラッパー機能を使って、53bit, 64bit, 106bit, 113bitの浮動小数点演算の速度を計測してみました。mpfrは、sudo apt install mpfr-devで入れたものです。
#include <kv/mpfr.hpp>
int main()
{
int i;
kv::mpfr<53> x;
x = 0.5; // 0.4 < x < 0.6
for (i=0; i<1000000000; i++) {
x = 1 / (x * (x - 1)) + 4.6;
}
std::cout << x << std::endl;
}
このプログラム中の53の部分を変えながら計測してみました。$ c++ -O3 mpfr53.cc -lmpfr $ time ./a.out 0.487308 real 3m54.608s user 3m50.821s sys 0m0.044s $ c++ -O3 mpfr64.cc -lmpfr $ time ./a.out 0.447779 real 5m16.806s user 5m11.236s sys 0m0.111s $ c++ -O3 mpfr106.cc -lmpfr $ time ./a.out 0.576081 real 5m37.827s user 5m32.035s sys 0m0.111s $ c++ -O3 mpfr113.cc -lmpfr $ time ./a.out 0.547514 real 5m42.499s user 5m36.300s sys 0m0.241smpfrは、多倍長演算のプログラムとしては十分高速で定評がありますが、さすがに遅いですね。
倍精度以外の計算速度まとめ
| 数値型 | 計算時間(秒) |
|---|---|
| 単精度 (全長32bit, 仮数部24bit) | 5.371 |
| 倍精度 (全長64bit, 仮数部53bit) | 5.964 |
| Intel拡張倍精度 (全長80bit, 仮数部64bit) | 6.325 |
| double-double by qd (全長128bit, 仮数部106bit相当) | 48.05 |
| double-double by kv (全長128bit, 仮数部106bit相当) | 36.74 |
| double-double by kv with FMA (全長128bit, 仮数部106bit相当) | 29.66 |
| float128 (全長128bit, 仮数部113bit) | 99.68 |
| mpfr (仮数部53bit) | 230.8 |
| mpfr (仮数部64bit) | 311.2 |
| mpfr (仮数部106bit) | 332.0 |
| mpfr (仮数部113bit) | 336.3 |
変なベンチマークの力学系的性質
ここからはオマケです。一応、この反復式
x_{n+1} = \frac{1}{x_n(x_n-1)} + 4.6
をどうやって作ったのか種明かしをしておきましょう。区間[0.4,0.6]でこの右辺のグラフを書くと、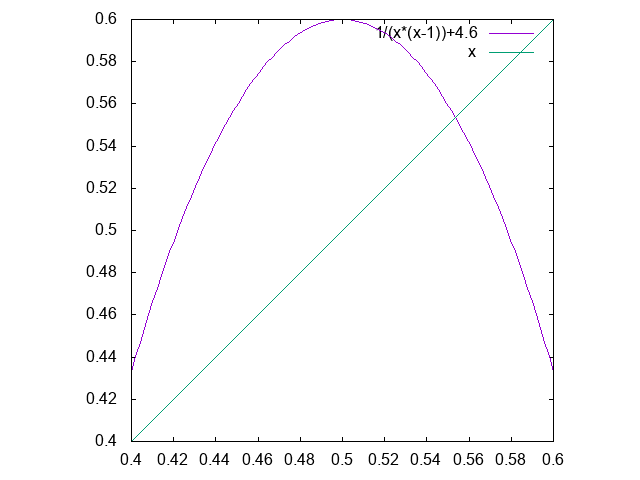
のようになります。すなわち、区間[0.4,0.6]から区間[0.4,0.6]への写像で、いわゆるロジスティック写像に形を似せて、カオスの発生を期待しました。
これが本当にカオスになっているのか自分の知識ではよく分かりませんが、安定な不動点、あるいは安定なn周期点があるとそこに吸い込まれてしまうので、それらが不安定である必要があります。不動点~5周期点までを探索してその安定性を調べてみたら、
| 周期点 | 傾き |
|---|---|
| 不動点 | |
| [0.55356306259771814,0.55356306259771904] | [-1.7540458821004337,-1.7540458821003905] |
| 2周期点 | |
| [0.47251229982482656,0.47251229982483978] | [-2.6496000000100227,-2.6495999999899826] |
| [0.58787417360511429,0.58787417360512307] | [-2.649600000013118,-2.6495999999869042] |
| 4周期点 | |
| [0.45660292682622499,0.45660292682782184] | [-6.994344006430338,-6.9943413287099849] |
| [0.56963838378845921,0.56963838379004439] | [-6.9943442880413019,-6.994341047098123] |
| [0.52087302149875114,0.52087302149987225] | [-6.9943435009524846,-6.9943418341871632] |
| [0.59301690190605937,0.59301690190710344] | [-6.9943446375696477,-6.9943406975699096] |
| 5周期点1 | |
| [0.49241639587271796,0.49241639589626041] | [-5.3195999647673152,-5.3191146240917346] |
| [0.59907961143524002,0.59907961146046785] | [-5.3210234368141052,-5.3176911750450219] |
| [0.43651199326412942,0.43651199328730845] | [-5.319869439031236,-5.3188451535460181] |
| [0.53445153616664387,0.5344515362008826] | [-5.3198513032572504,-5.3188632923945835] |
| [0.58091887627954896,0.58091887630723616] | [-5.3198877237365352,-5.3188268706445134] |
| 5周期点2 | |
| [0.43930700020768825,0.4393070002409904] | [7.3230674094215144,7.3246535122595358] |
| [0.54018034001802039,0.54018034004123794] | [7.3234484071188221,7.3242725048956273] |
| [0.57400074538735523,0.57400074542057201] | [7.3231434952559464,7.3245774251428078] |
| [0.51042003579714645,0.51042003582068152] | [7.3235356733528114,7.3241852373848194] |
| [0.59826201082553276,0.59826201084694897] | [7.3224303075700802,7.3252906173775747] |