検索条件
全1件
(1/1ページ)
sudo apt install libblas-devLAPACKと一緒に配布されているBLAS。入出力インターフェースのReferenceを与える、という意味合いと思われ、中身は単なるfor文で高速化を考慮したものではありません。
sudo apt install libatlas-base-devCPUの特性に合わせて自動的に各種パラメータをチューニングして性能を引き出すBLASです。make時に何通りもの大きさの計算を繰り返して最適な大きさを探るため、makeにはものすごく時間がかかります。実行するマシン上でmakeしないと意味がないので、aptによるbinary配布では本来の性能は発揮できないはずです。
sudo apt install libblis-devUbuntu 20.04で使えるBLASを探していて、今回初めて知ったBLAS実装です。最近できたものでしょうか。AOCL (AMD Optimizing CPU Libraries) で採用されていたので、AMDのCPUに強いのかも知れません。
sudo apt install libopenblas-base sudo apt install libopenblas-dev有名なオープンソース実装のBLAS。かつて、GotoBLASというテキサス大学の後藤和茂氏による高速で有名なBLAS実装があって、その後藤氏のIntelへの移籍で開発が中断したとき、有志がそのソースコードを引き継いで発展させたものです。その後藤氏は現在Intelで後述のMKLに関わっているそうです。
sudo apt install intel-mklIntelが提供している、BLASを含む数学用ソフトウェアパッケージで、オープンソースではありません。最近、aptで簡単にインストールできるようになりました。極めて高速とされています。
sudo update-alternatives --config libblas.so-x86_64-linux-gnuとすると、
There are 5 choices for the alternative libblas.so-x86_64-linux-gnu (providing /usr/lib/x86_64-linux-gnu/libblas.so). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so 100 auto mode 1 /usr/lib/x86_64-linux-gnu/atlas/libblas.so 35 manual mode * 2 /usr/lib/x86_64-linux-gnu/blas/libblas.so 10 manual mode 3 /usr/lib/x86_64-linux-gnu/blis-openmp/libblas.so 80 manual mode 4 /usr/lib/x86_64-linux-gnu/libmkl_rt.so 1 manual mode 5 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so 100 manual mode Press <enter> to keep the current choice[*], or type selection number:のように表示され、「*」の印がついたライブラリが現在使われているもので、番号を入れるとそのライブラリに切り替えることができます。これはlibblas.soを切り替えるものですが、libblas.so.3も同様にupdate-alternativesの管理下にあるようで、念の為そちらも同じように切り替えて実験しました。
sudo update-alternatives --config libblas.so.3-x86_64-linux-gnu
There are 5 choices for the alternative libblas.so.3-x86_64-linux-gnu (providing /usr/lib/x86_64-linux-gnu/libblas.so.3). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3 100 auto mode 1 /usr/lib/x86_64-linux-gnu/atlas/libblas.so.3 35 manual mode * 2 /usr/lib/x86_64-linux-gnu/blas/libblas.so.3 10 manual mode 3 /usr/lib/x86_64-linux-gnu/blis-openmp/libblas.so.3 80 manual mode 4 /usr/lib/x86_64-linux-gnu/libmkl_rt.so 1 manual mode 5 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3 100 manual mode Press <enter> to keep the current choice[*], or type selection number:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// prototype declaration
void dgemm_(char *transA, char *transB, int *m, int *n, int *k, double *alpha, double *A, int *ldA, double *B, int *ldB, double *beta, double *C, int *ldC);
int main(int argc, char **argv)
{
int i, j;
int m, n, k;
int size;
double *a, *b, *c;
double alpha, beta;
int lda, ldb, ldc;
struct timespec ts1, ts2;
size = atoi(argv[1]);
m = size;
n = size;
k = size;
a = (double *)malloc(sizeof(double) * m * k); // m x k matrix
b = (double *)malloc(sizeof(double) * k * n); // k x n matrix
c = (double *)malloc(sizeof(double) * m * n); // m x n matrix
for (i=0; i<m; i++) {
for (j=0; j<k; j++) {
a[i + m * j] = rand() / (1.0 + RAND_MAX);
}
}
for (i=0; i<k; i++) {
for (j=0; j<n; j++) {
b[i + k * j] = rand() / (1.0 + RAND_MAX);
}
}
for (i=0; i<m; i++) {
for (j=0; j<n; j++) {
c[i + m * j] = 0;
}
}
alpha = 1.;
beta = 0.;
lda = m;
ldb = k;
ldc = m;
// dgemm_(TransA, TransB, M, N, K, alpha, A, LDA, B, LDB, beta, C, LDC)
// C = alpha * A * B + beta * C
// A=M*K, B=K*N, N=M*N
// Trans: "N"/"T"/"C"
// LDA = number of row of A
clock_gettime(CLOCK_REALTIME, &ts1);
dgemm_("N", "N", &m, &n, &k, &alpha, a, &lda, b, &ldb, &beta, c, &ldc);
clock_gettime(CLOCK_REALTIME, &ts2);
printf("%g\n", (ts2.tv_sec - ts1.tv_sec) + (ts2.tv_nsec - ts1.tv_nsec) / 1e9);
free(a);
free(b);
free(c);
return 0;
}
BLASはFortranで書かれていて、C言語から呼びやすくしたcblasというインターフェースもあるのですが、ここでは直接BLASを呼び出しています。n×n行列を2つ乱数で初期化し、その積を求めています。また、参考のために単なるfor文のi-j-k loopで書いた行列積のプログラムとも比較してみました。そのプログラムは以下の通り。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
double **alloc_matrix(int n, int m)
{
double **a;
int i;
a = (double **)malloc(sizeof(double *) * n);
a[0] = (double *)malloc(sizeof(double) * n * m);
for (i=1; i<n; i++) {
a[i] = a[0] + i * m;
}
return a;
}
void free_matrix(double **a)
{
free(a[0]);
free(a);
}
// a: n x m, b: m x s, c: n x s
void m_m_mul(double **a, double **b, double **c, int n, int m, int s)
{
int i, j, k;
int i1, j1, k1;
for (i=0; i<n; i++) {
for (j=0; j<s; j++) {
c[i][j] = 0.0;
}
}
for (i=0; i<n; i++) {
for (j=0; j<s; j++) {
for (k=0; k<m; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
int main(int argc, char **argv)
{
int i, j, n;
double **a;
double **b;
double **c;
struct timespec ts1, ts2;
n = atoi(argv[1]);
a = alloc_matrix(n,n);
b = alloc_matrix(n,n);
c = alloc_matrix(n,n);
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
a[i][j] = rand()/(1.0 + RAND_MAX);
b[i][j] = rand()/(1.0 + RAND_MAX);
}
}
clock_gettime(CLOCK_REALTIME, &ts1);
m_m_mul(a, b, c, n, n, n);
clock_gettime(CLOCK_REALTIME, &ts2);
printf("%g\n", (ts2.tv_sec - ts1.tv_sec) + (ts2.tv_nsec - ts1.tv_nsec) / 1e9);
free_matrix(a);
free_matrix(b);
free_matrix(c);
return 0;
}
これらを、cc -O3 dgemm.c -lblas cc -O3 forloop.cのようにコンパイルしました。
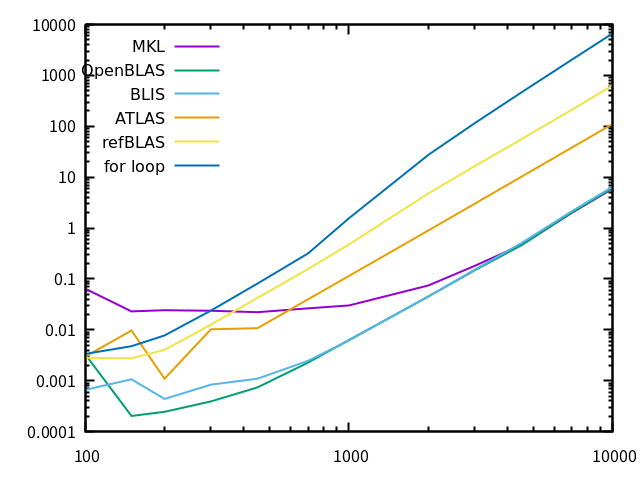
OMP_NUM_THREADS=8 ./a.outのように環境変数をつけてあげるとその数のコアを使って計算しますが、何も付けないとシングルコアになりました。ATLAS、Reference BLASはシングルコア計算でした (ATLASはこのマシンでmakeすればマルチコアを使うはずです、念の為)。