2024/05/02(木)Ubuntu 24.04 インストール (2)
- デスクトップのリサイズ、
- ホストOSとのクリップボード共有(文字列のコピペが出来るようになる)、
- フォルダ共有
sudo apt install open-vm-tools-desktopとしましょう。
共有フォルダは、vmwareの「VM→Settings→Option→Shared Folders」をAlways Enabledにし、Addで適当なフォルダを共有フォルダに指定、再起動。
sudo vmhgfs-fuse -o allow_other -o auto_unmount .host:/ /mnt/hgfsで/mnt/hgfs以下にマウント出来ました。永続的にmountするには、/etc/fstabで
.host:/ /mnt/hgfs fuse.vmhgfs-fuse allow_other,auto_unmount,defaults 0 0と書くとよいでしょう。
2024/05/02(木)Ubuntu 24.04 インストール (1)
Ubuntuの24.04というのは2024年4月のバージョンという意味です。Ubuntuは22.04, 22.10, 23.04...のように半年に一度新しいものが出ますが、基本的に9ヶ月のサポート期間のところ、偶数年の4月に出るバージョン(LTS)は5年のサポート期間があります。Ubuntu 24.04は、2024年4月25日にリリースされました。
インストール用のisoファイルは、http://releases.ubuntu.com/24.04/からubuntu-24.04-desktop-amd64.isoをダウンロードしました。
インストールは、Linux版のVMwareで行ったので、メニューの項目が英語になってます。File→New Virtual Machine→Create a New Virtual Machine→Typical (recommended)
→I will install the operationg system later→Linux→Ubuntu 64bitの手順で仮想マシンを作成。ディスクはデフォルトの20Gじゃ少ないので512Gに増やしました (ここを多くしても実際に仮想マシン内で使用しない限りホストマシンのディスクを圧迫することはありません)。メモリはとりあえずデフォルトの4Gで (こちらは大きくするだけホストマシンのメモリを食います)。VM→Settings→CD/DVDでダウンロードしたisoをマウントし起動。
- 「Install Ubuntu」とし、言語は「日本語」を選ぶ。
- キーボードレイアウトは「日本語」「日本語」
- アクセシビリティは、何もせず「Next」
- インターネットの接続方法は「有線接続を使用」
- 「Ubuntuをインストール」「対話式インストール」
- インストールセットは、「既定の選択」(最小限のWebブラウザーと基本的なユーティリティのみです。)と、「拡張選択」(オフィスツール、ユーティリティにWebブラウザーを含み、オフラインに優しい選択です。)が選べるようになっていましたが、「拡張選択」
- 「グラフィックスとWi-Fi機器用のサードパーティ製ソフトウェアをインストールする」、「追加のメディアフォーマット用のサポートをダウンロードしてインストールする」をチェック。
- 「ディスクを削除してUbuntuをインストールする」を選ぶ。
- ユーザ作成時、「ログイン時にパスワードを要求する」はチェックしたままにする。
- タイムゾーンは「Asia/Tokyo」
とりあえず端末を出すには、右下の丸いアイコンをクリックして「端末」を選びます。右クリックして「お気に入りへ追加」するといいでしょう。
日本語をかな漢字変換で入力するには、インストール直後の一回だけ、右上の「ja」をクリックして、「日本語(Mozc)」を選ぶ必要があります。
2022/06/13(月)Ubuntu LinuxでVMware Workstation pro/playerを使うときの注意
UbuntuでVMwareを使うときの特別な設定を備忘録も兼ねて書いておきます。誰かの役に立つかもしれないので。
ゲストが異常に重くなる現象への対策
特に複数ゲストを起動したときなどに、ゲストがほとんど操作不能なレベルで重くなってしまい、そのときホストではkcompactd0というプロセスのCPU使用率が100%になっている、という現象が見られることがあります。数分待つと解消しますが、またすぐに再発します。これは多くの人が悩まされ決定的な対策はなかなか見つからなかったのですが、にあるように最近対策が見つかりました。rootで(sudo suとかした後に)、
echo 0 > /proc/sys/vm/compaction_proactivenessとすると立ちどころに収まります。永続的にこれを設定するには、/etc/sysctl.confに
vm.compaction_proactiveness=0と書き加えて再起動すればいいようです。
Ubuntu 22.04でVMware Workstationを使う
現時点でVMware Workstationの最新版は16.2.3-19376536ですが、これはまだUbuntu 22.04の新しいカーネルに対応していないようで、初回起動時のカーネルモジュールのコンパイルでエラーになってしまい、起動することができません。そのうち対応するでしょうけど、とりあえず、にあるように、
git clone https://github.com/mkubecek/vmware-host-modules cd vmware-host-modules git checkout workstation-16.2.3 make clean make sudo make install sudo modprobe -a vmw_vmci vmmon vmnet sudo service vmware restartで起動するようになりました。
NATを使ったとき、断続的にネットワークがON/OFFを繰り返す
ゲストOSのネットワークをNATにしたとき、ゲストOSの種類には関係なく、断続的に(10秒周期くらい?)ゲストのネットワークがON/OFFを繰り返す、という困った現象に遭遇しました。Ubuntu 22.04にVMware Workstationを入れたときに発生したのですが、別のマシンにUbuntu 22.04とVMware Workstationを入れて発生しないケースもあったので、発生する条件はよく分かりません。 (2022/6/15追記: その別のマシンでもこの現象を確認しました。当方の環境では、Ubuntu 22.04にしたことで2/2で発生。) 検索してみると、- https://communities.vmware.com/t5/VMware-Workstation-Pro/Vmware-disconnected-and-reconnects-frequently/td-p/2267837
- http://sgros.blogspot.com/2015/10/vmware-workstation-1011-on-fedora-23.html
- https://web.archive.org/web/20210301012537/https://www.nikhef.nl/~janjust/vmnet/
- https://superuser.com/questions/1452729/prevent-a-program-vmet-natd-from-getting-events-that-the-network-has-changed-s
May 21 17:43:44 exa kernel: [14661.785888] userif-3: sent link up event. May 21 17:43:47 exa kernel: [14664.977941] userif-3: sent link down event. May 21 17:43:47 exa kernel: [14664.977949] userif-3: sent link up event. May 21 17:43:52 exa kernel: [14669.758177] userif-3: sent link down event. May 21 17:43:52 exa kernel: [14669.758186] userif-3: sent link up event. May 21 17:44:00 exa kernel: [14677.442456] userif-3: sent link down event. May 21 17:44:00 exa kernel: [14677.442465] userif-3: sent link up event. May 21 17:44:03 exa kernel: [14680.650489] userif-3: sent link down event.のようなログが残っていました。そこで、前の節で入れたカーネルモジュールのvmware-host-modules/vmnet-only/userif.cに、強引ですが
*** userif.c.original 2022-05-15 22:05:24.140904301 +0900
--- userif.c 2022-05-21 17:43:37.199281561 +0900
***************
*** 1002,1007 ****
--- 1002,1010 ----
return -EINVAL;
}
+ /* never send link down events */
+ if (!linkUp) return 0;
+
if (userIf->eventSender == NULL) {
/* create event sender */
retval = VNetHub_CreateSender(hubJack, &userIf->eventSender);
のようにlink downイベントを発生しないようにパッチを当ててモジュールを再インストールしたら、問題は解決しました。おわりに
おそらく、VMwareがバージョンアップしたら不要になる情報かもしれませんが、自分がこれらの情報に行き着くまでに結構苦労したので、こうしてまとめておけば誰かの役に立つかもしれないと思い、こうして情報を残しておきます。2022/05/13(金)Ubuntu 22.04のBLAS (dgemm) をベンチマーク
BLAS, LAPACKとは何か、個々のBLASの特徴などは、20.04のときの記事を見て下さい。前回と同様、Reference BLAS, ATLAS, OpenBLAS, BLIS, MKLの5つのパッケージをaptでインストールし、dgemmを呼び出して計算時間を計測するプログラムを使って、update-alternativesの機能でlibblas.soを切り替えながらベンチマークを取り、計算時間を比較します。前回と大雑把な傾向はほとんど変わっていないのですが、MKLのパッケージが怪しげな挙動を示した(ような気がした)ので備忘録として書いています。
各BLASのインストール方法
- Reference BLAS
apt install libblas-dev
- ATLAS
apt install libatlas-base-dev
- OpenBLAS
apt install libopenblas-base apt install libopenblas-dev
- BLIS
apt install libblis-dev
- MKL
apt install intel-mkl最後のMKLですが、aptの実行中に
Use libmkl_rt.so as the default alternative to BLAS/LAPACK? [yes/no]と聞かれます。これには「no」と答えました。「yes」と答えると、「-lblas」を付けてコンパイルしたものはlibblas.soがリンクされずにMKL(libmkl_rt.so)がリンクされてしまってupdate-alternativesでlibblas.soの実体を切り替える作戦が不可能になってしまいました。何か自分が勘違いしてるのかも知れません。
これらのライブラリは、
update-alternatives --config libblas.so-x86_64-linux-gnuとすると
There are 5 choices for the alternative libblas.so-x86_64-linux-gnu (providing /usr/lib/x86_64-linux-gnu/libblas.so). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so 100 auto mode 1 /usr/lib/x86_64-linux-gnu/atlas/libblas.so 35 manual mode 2 /usr/lib/x86_64-linux-gnu/blas/libblas.so 10 manual mode * 3 /usr/lib/x86_64-linux-gnu/blis-openmp/libblas.so 80 manual mode 4 /usr/lib/x86_64-linux-gnu/libmkl_rt.so 1 manual mode 5 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so 100 manual mode Press <enter> to keep the current choice[*], or type selection number:と表示され、libblas.soの実体をsymbolic linkで切り替えることができます。libblas.so.3の方も同様に
update-alternatives --config libblas.so.3-x86_64-linux-gnu
There are 5 choices for the alternative libblas.so.3-x86_64-linux-gnu (providing /usr/lib/x86_64-linux-gnu/libblas.so.3). Selection Path Priority Status ------------------------------------------------------------ 0 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3 100 auto mode 1 /usr/lib/x86_64-linux-gnu/atlas/libblas.so.3 35 manual mode 2 /usr/lib/x86_64-linux-gnu/blas/libblas.so.3 10 manual mode * 3 /usr/lib/x86_64-linux-gnu/blis-openmp/libblas.so.3 80 manual mode 4 /usr/lib/x86_64-linux-gnu/libmkl_rt.so 1 manual mode 5 /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3 100 manual mode Press <enter> to keep the current choice[*], or type selection number:と切り替えることができ、前回と同様、両方を同じものに切り替えて実験を行いました。
ベンチマーク
dgemmの実行時間計測に使ったプログラムは、以下のようなものです。前回の20.04のときと同じです。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// prototype declaration
void dgemm_(char *transA, char *transB, int *m, int *n, int *k, double *alpha, double *A, int *ldA, double *B, int *ldB, double *beta, double *C, int *ldC);
int main(int argc, char **argv)
{
int i, j;
int m, n, k;
int size;
double *a, *b, *c;
double alpha, beta;
int lda, ldb, ldc;
struct timespec ts1, ts2;
size = atoi(argv[1]);
m = size;
n = size;
k = size;
a = (double *)malloc(sizeof(double) * m * k); // m x k matrix
b = (double *)malloc(sizeof(double) * k * n); // k x n matrix
c = (double *)malloc(sizeof(double) * m * n); // m x n matrix
for (i=0; i<m; i++) {
for (j=0; j<k; j++) {
a[i + m * j] = rand() / (1.0 + RAND_MAX);
}
}
for (i=0; i<k; i++) {
for (j=0; j<n; j++) {
b[i + k * j] = rand() / (1.0 + RAND_MAX);
}
}
for (i=0; i<m; i++) {
for (j=0; j<n; j++) {
c[i + m * j] = 0;
}
}
alpha = 1.;
beta = 0.;
lda = m;
ldb = k;
ldc = m;
// dgemm_(TransA, TransB, M, N, K, alpha, A, LDA, B, LDB, beta, C, LDC)
// C = alpha * A * B + beta * C
// A=M*K, B=K*N, N=M*N
// Trans: "N"/"T"/"C"
// LDA = number of row of A
clock_gettime(CLOCK_REALTIME, &ts1);
dgemm_("N", "N", &m, &n, &k, &alpha, a, &lda, b, &ldb, &beta, c, &ldc);
clock_gettime(CLOCK_REALTIME, &ts2);
printf("%g\n", (ts2.tv_sec - ts1.tv_sec) + (ts2.tv_nsec - ts1.tv_nsec) / 1e9);
free(a);
free(b);
free(c);
return 0;
}
単なる比較のための、単純な三重forループによる行列積のプログラムは、以下の通り。これも前回と同じ。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
double **alloc_matrix(int n, int m)
{
double **a;
int i;
a = (double **)malloc(sizeof(double *) * n);
a[0] = (double *)malloc(sizeof(double) * n * m);
for (i=1; i<n; i++) {
a[i] = a[0] + i * m;
}
return a;
}
void free_matrix(double **a)
{
free(a[0]);
free(a);
}
// a: n x m, b: m x s, c: n x s
void m_m_mul(double **a, double **b, double **c, int n, int m, int s)
{
int i, j, k;
int i1, j1, k1;
for (i=0; i<n; i++) {
for (j=0; j<s; j++) {
c[i][j] = 0.0;
}
}
for (i=0; i<n; i++) {
for (j=0; j<s; j++) {
for (k=0; k<m; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
}
int main(int argc, char **argv)
{
int i, j, n;
double **a;
double **b;
double **c;
struct timespec ts1, ts2;
n = atoi(argv[1]);
a = alloc_matrix(n,n);
b = alloc_matrix(n,n);
c = alloc_matrix(n,n);
for (i=0; i<n; i++) {
for (j=0; j<n; j++) {
a[i][j] = rand()/(1.0 + RAND_MAX);
b[i][j] = rand()/(1.0 + RAND_MAX);
}
}
clock_gettime(CLOCK_REALTIME, &ts1);
m_m_mul(a, b, c, n, n, n);
clock_gettime(CLOCK_REALTIME, &ts2);
printf("%g\n", (ts2.tv_sec - ts1.tv_sec) + (ts2.tv_nsec - ts1.tv_nsec) / 1e9);
free_matrix(a);
free_matrix(b);
free_matrix(c);
return 0;
}
これらは、cc -O3 dgemm.c -lblas cc -O3 forloop.cのようにコンパイルします。ただし、dgemm.cの方のコンパイルをするときに、update-alternativesの選択をMKL以外にする必要がありました。MKLの状態でコンパイルすると、libblas.soがリンクされずにlibmkl_rt.soがリンクされてしまって、update-alternativesによる事後切り替えが不可能なbinaryができてしまいました。これもまた自分の勘違いかも。
さて、ベンチマークの結果は以下のようになりました。使ったCPUはcore i7 1195G7 (ノートPC) で、前回と異なるので絶対値には意味がないかも。
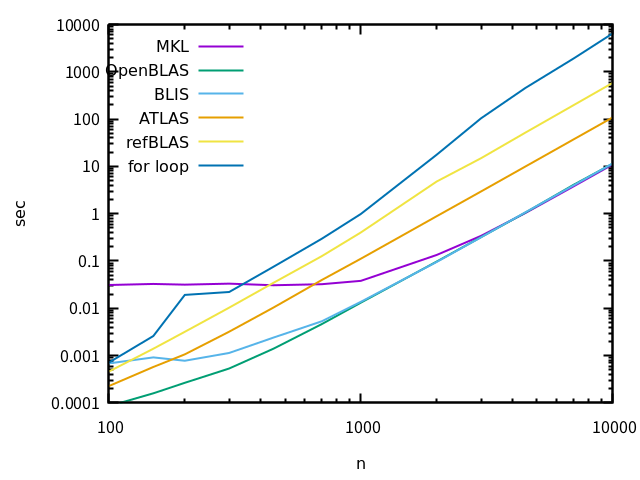
前回と似たような結果ですね。最速はOpenBLAS, BLIS, MKL。小サイズでMKLが妙に遅いのも同じ。
2022/04/30(土)ubuntu 22.04 インストール (リンク集)
- ubuntu 22.04 インストール (1)
- ubuntu 22.04 インストール (2) vmware tools
- ubuntu 22.04 インストール (3) TeX関連
- ubuntu 22.04 インストール (4) vim
- ubuntu 22.04 インストール (5) プログラミング系あれこれ
- ubuntu 22.04 インストール (6) apache,php
- ubuntu 22.04 インストール (7) samba
- ubuntu 22.04 インストール (8) マルチメディア系
- ubuntu 22.04 インストール (9) docker
- ubuntu 22.04 インストール (10) その他