2016/10/31(月)bash on Ubuntu on Windowsを試してみる
cygwinやmsys2など、Windows上でunixツールを使うためのものは以前からいろいろありますが、Microsoft本家が出してきたこいつは、「ubuntuのバイナリがそのまま動く」という点が今までと違います。使うための条件は、
- Windows10の64bit版であること
- Windows10のバージョン1607以降であること
8月のリリース以降、少しずつ時間をずらしながらWindows Updateを降らせていたようですが、そろそろほとんどのWindows10が1607になった頃ではないでしょうか。

インストール
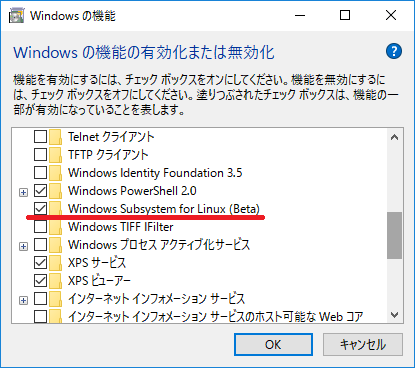
インストール方法の情報は検索すればたくさん出てきますが、次のような手順です。- 「スタートを右クリック→プログラムと機能→Windowsの機能の有効化または無効化」で、「Windows Subsysyem for Linux (Beta)」をチェックする。再起動。
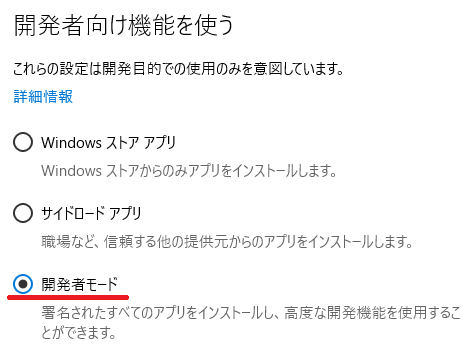
- 「スタート→歯車アイコン→更新とセキュリティ→開発者向け」で、「開発者モードを使う」を、「サイドロードアプリ」から「開発者モード」に変更。再起動。
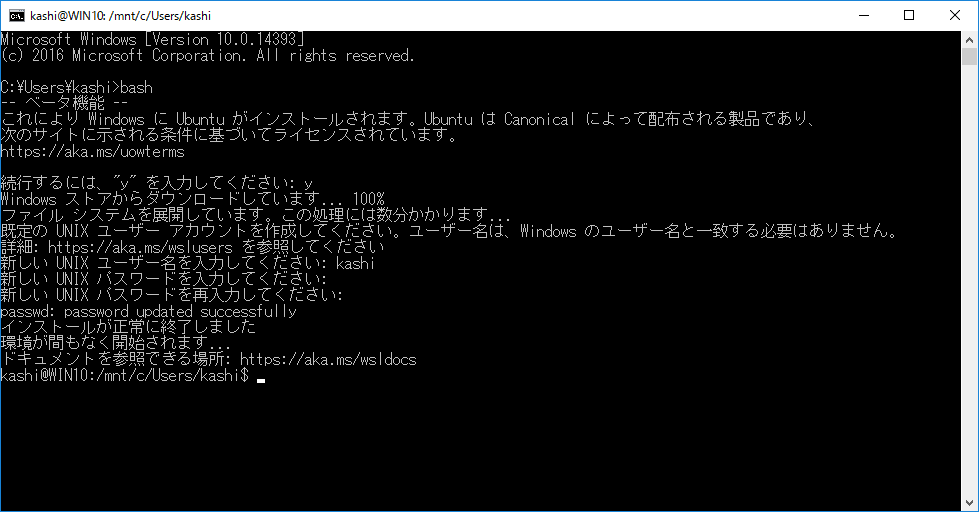
- 「スタートを右クリック→コマンドプロンプト」でコマンドプロンプトを起動し、bashとタイプ。"y"でダウンロードとインストールが始まります。数分かかります。ユーザIDとパスワードを聞かれてインストール完了。
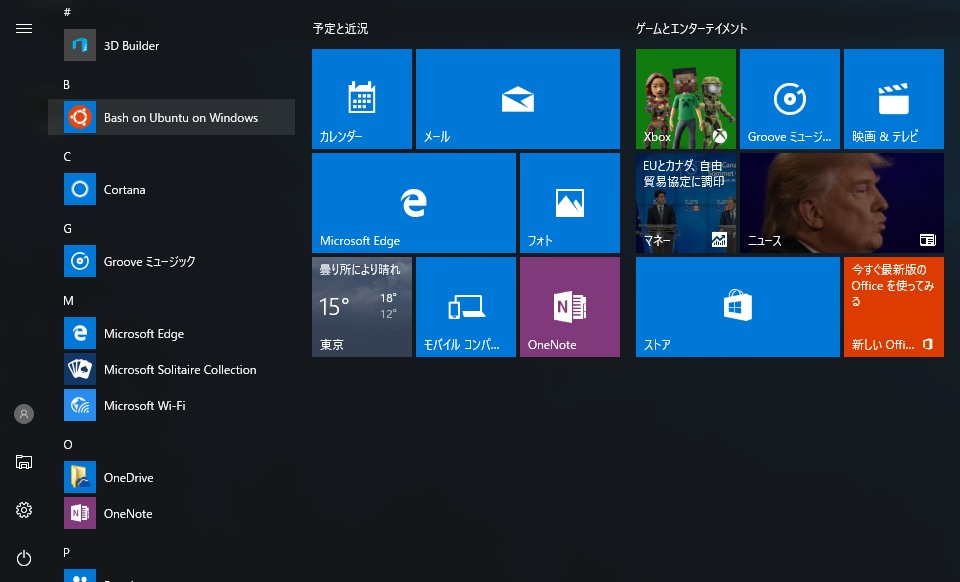
- 次回以降は、スタートメニューに「Bash on Ubuntu on Windows」が登録されているのでそこから起動できます。
アンインストール
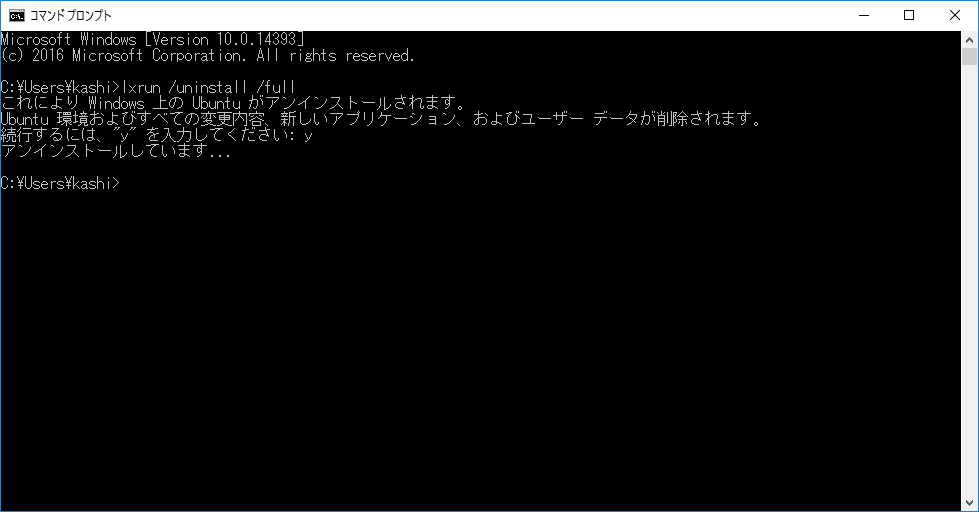
いろいろ試しにパッケージを入れたりしてシステムが壊れることもあるかと思いますが、コマンドプロンプトでlxrun /uninstall /fullと入れるときれいさっぱり削除できます。上の「bashとタイプ」のところからやりなおすことが出来ます。
簡単な使い方など
- 中身はubuntu 14.04です。いつものubuntuの作法通り、
sudo apt update sudo apt upgrade
で最新に更新しておきましょう。 - これで、端末内で完結するような作業は大体できます。最初は最低限しかインストールされていないので、いつものubuntuの作法で必要なパッケージをインストールしましょう。とりあえず
sudo apt install build-essential
でCコンパイラなど最低限の開発環境を入れることをお勧めします。 - ubuntu側からは、windows側のファイルが例えばCドライブなら
/mnt/c/
以下に見えます。逆にwindows側から見てubuntuのファイルシステムは
c:\Users\(windowsユーザ名)\AppData\Local\lxss\
にあり、このフォルダがubuntu側の"/"に対応しています。隠しファイルになっているので普通の状態では見えないかも知れません。恐らく、ubuntu側からwindowsのファイルシステムを操作することはOK、windows側からubuntuのファイルシステムを操作するのはNG、だと思われます。
- X windowを使うソフトウェアが動かない。gnuplotくらい使いたい!
- (文字幅を正しく扱えないせいか)日本語が頻繁に文字化けする。
- そもそも日本語が入力できない。
X環境を作る
買ったままのwindowsでソフトウェア追加無しにunix環境が使えるのがbash on ubuntu on windowsのメリットですが、windows用のX serverを入れてしまえば使えるソフトウェアが一気に増え、また日本語の問題も解決できる可能性があります。そこで、上記問題点を解決すべく、X serverを入れてみます。X serverは有料、無料いろいろあると思いますが、いろいろ検索してみると無料では
の2つがよく使われているようです。今回はXmingの方を使ってみました。Xming X Serverによると、Public Domain Releasesという無料版と、Website Releaseという新しいが寄付が必要な版があるようです。今回はPublic Domain Releasesの方を使いました。
- Xming 6.9.0.31
- Xming-fonts 7.7.0.10
スタートメニューから「Xming」を起動します。(「XLaunch」の方だといろいろオプションを設定してから起動します。今回はデフォルトのままで十分。) すると、右下に
のようなアイコンが出ます。これで、bash on ubuntu on windowsからの描画命令を受け止める準備が出来たことになります。動作チェックします。

sudo apt install x11-apps sudo apt install x11-utils sudo apt install x11-xserver-utilsといくつかのx11の基本アプリをインストールして、
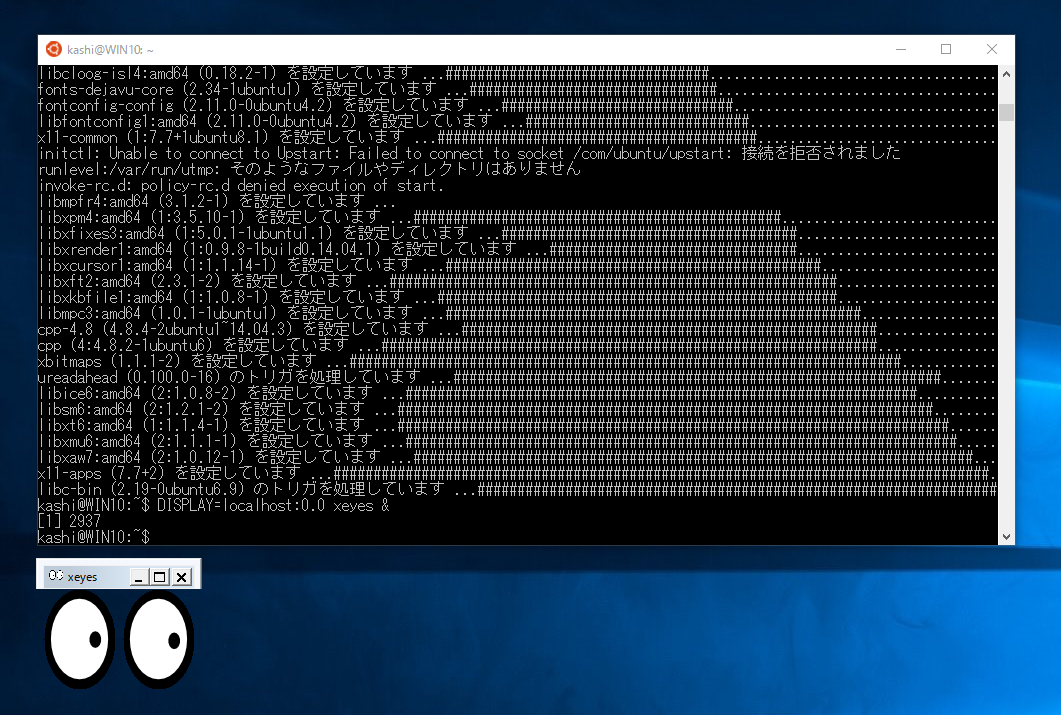
DISPLAY=localhost:0.0 xeyes &とxeyesを起動してみます。
のようにマウスカーソルを追う目玉が表示されたら、正常に動作しています。
gnuplotを試してみましょう。
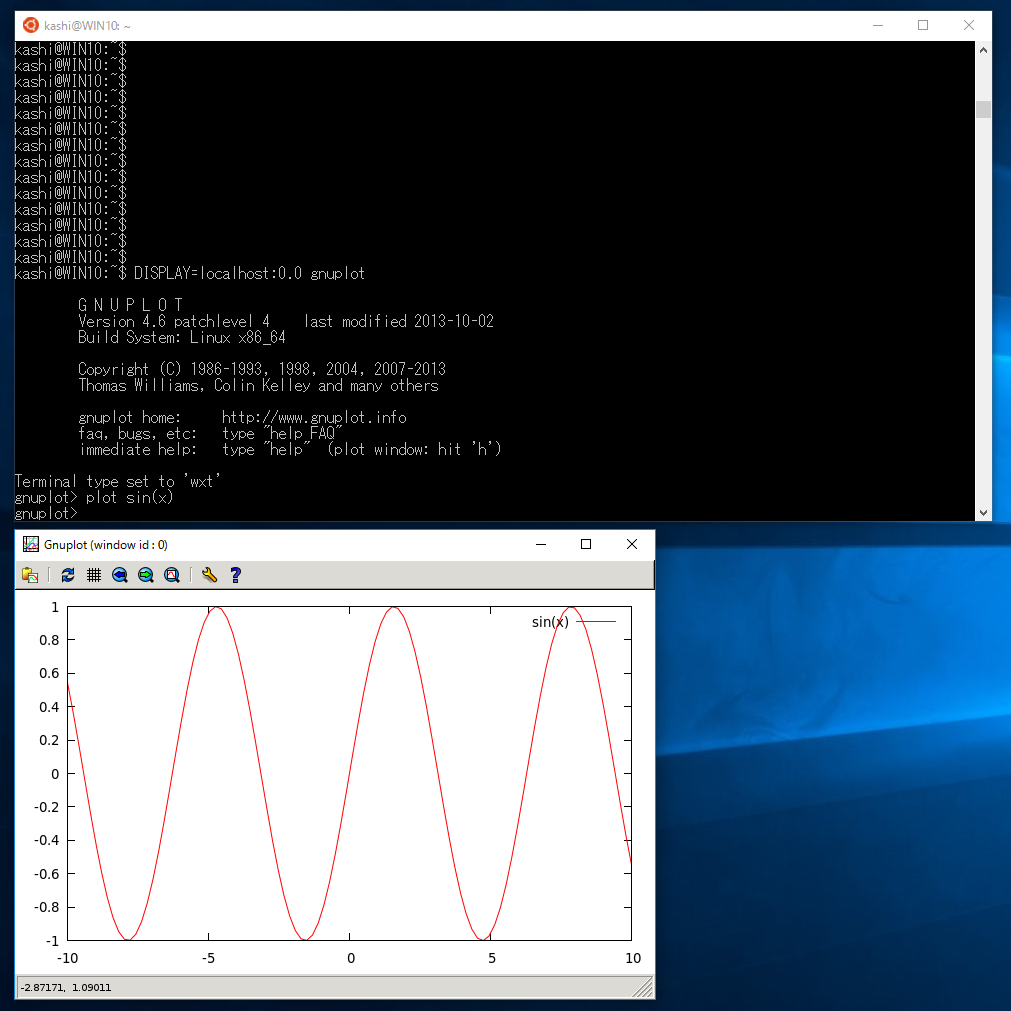
sudo apt install gnuplot-x11としてインストールし、
DISPLAY=localhost:0.0 gnuplotとして起動します。
のように、ちゃんと動作しました。毎回「DISPLAY=localhost:0.0」とするのが面倒なら、
export DISPLAY=localhost:0.0とすると、端末を閉じるまで有効になります。
驚くべきことに、日本語フォントを追加してやると、少しエラーが出るもののfirefoxを動かすことができます。
sudo apt install fonts-ipafont sudo apt install firefox
日本語環境を整える
ここまでちゃんと動作するとなると、日本語の読み書きがまともにできないのが惜しくなってきます。そこで、少し頑張って環境を整えてみました。いろいろ試行錯誤した結果ではありますが、もっといい方法もありそうなので情報が欲しいところです。以下、自分が試した方法を書きます。X serverがwindows側にインストールしてあって、また上で書いたように、sudo apt install fonts-ipafontで日本語フォントを追加してあるものとします。
まず、端末は、windows側を捨ててXの方で動かすことにします。いろいろ試しましたが、lxterminalが良さそうでした。
sudo apt install lxterminalでインストールし、
DISPLAY=localhost:0.0 lxterminal &で起動します。起動後に「編集→設定」でフォントをMonoSpace 10からMonospace 15くらいにしてあげると見やすい感じになりました。
windows側の端末を使わずにこちらを使うことにします。こちらからだと「DISPLAY=locahost:0.0」をいちいち打たなくてよくなります。windows側の端末を閉じると全部落ちてしまうので、アイコンにでもしておきましょう。
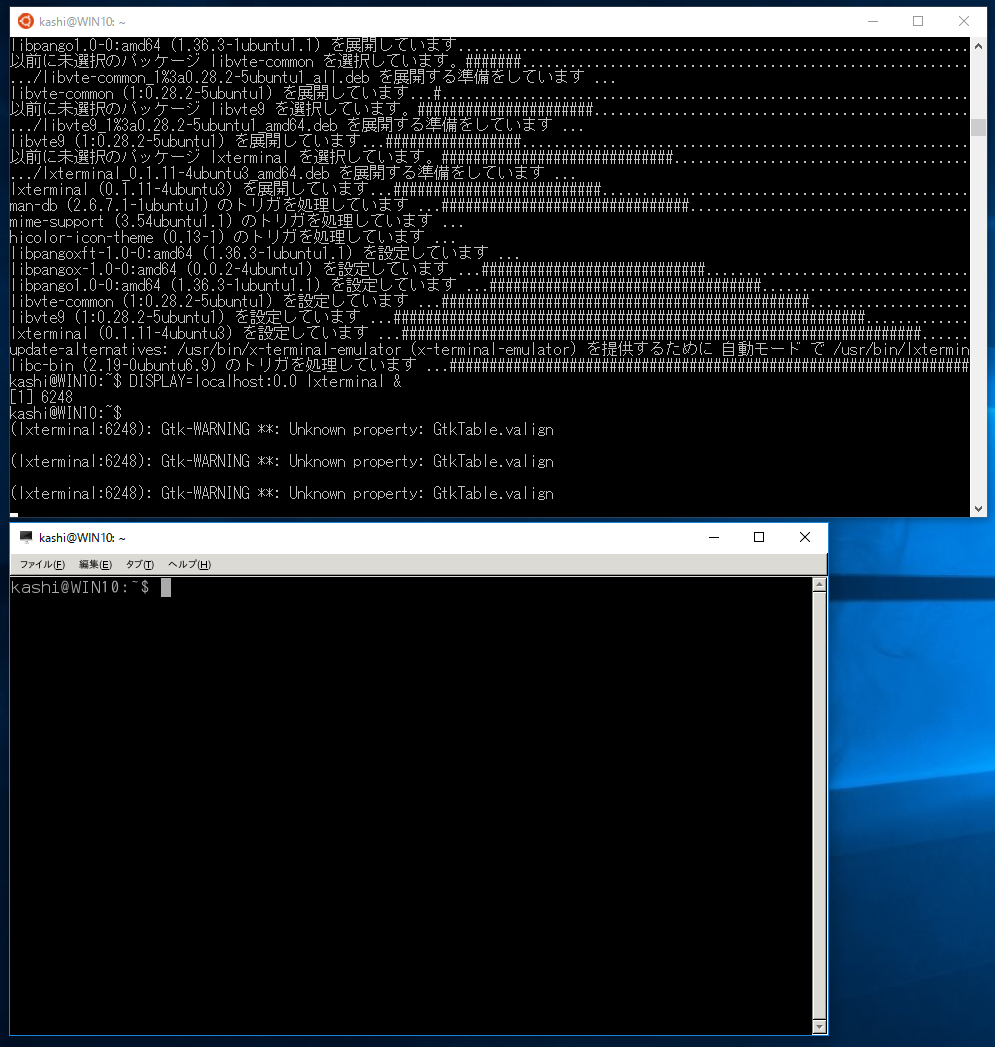
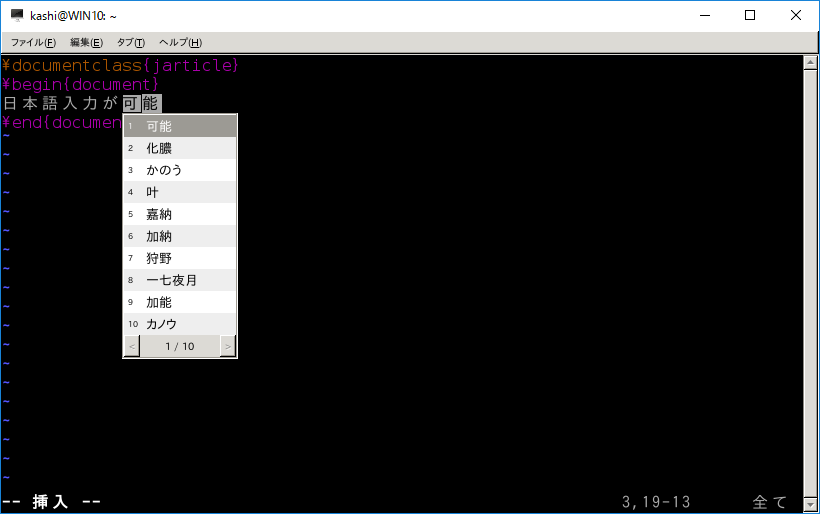
かな漢字変換のシステムを入れます。いろいろ試しましたが、uim-anthyが何とか動作しました。
sudo apt install uim uim-xim uim-anthyのようにインストールします。そして、windows側のbashターミナルで、
DISPLAY=localhost:0.0 UIM_CANDWIN_PROG=uim-candwin-gtk uim-xim &のようにかな漢字変換サーバを起動し、lxterminalの起動は
DISPLAY=localhost:0.0 XMODIFIERS="@im=uim" GTK_IM_MODULE=uim QT_IM_MODULE=uim lxterminal &とします。これで、「半角/全角」キーで日本語入力ができるようになりました。
terminal起動時の設定が長いですが、このterminalから起動したものにはこの設定が伝わるので、ここからいろいろ起動することにすれば楽です。
その他もろもろ
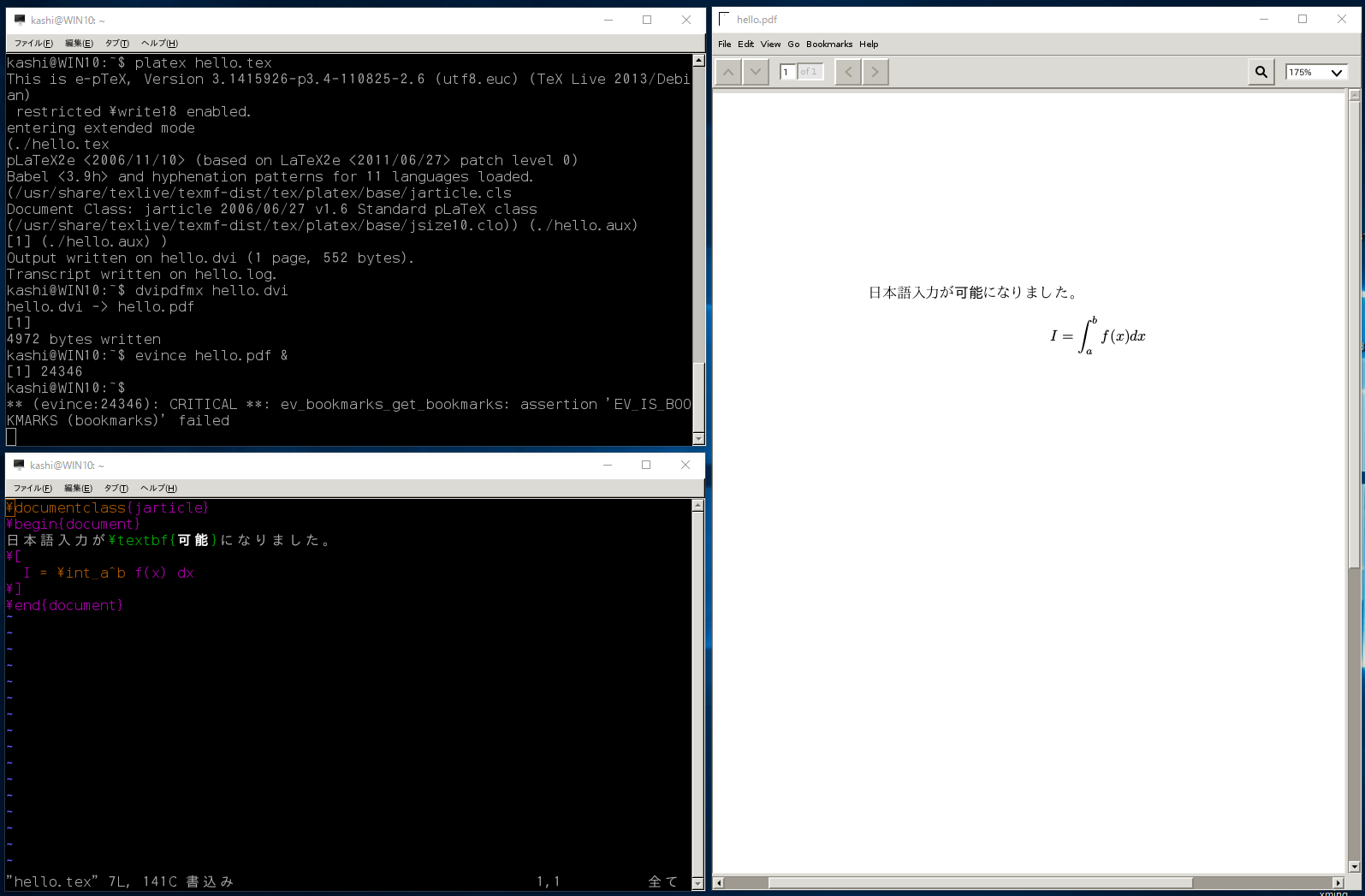
他にもいろいろ入れてみました。TeX環境。
sudo apt install texlive-lang-cjkで簡単に入ります(ちょっと時間がかかります)。ついでに
sudo apt install evinceでpdfビューアも。
java。
sudo apt install default-jdkあちこちでjavaは動かないという記述を見かけましたが、普通に動いているように見えます。
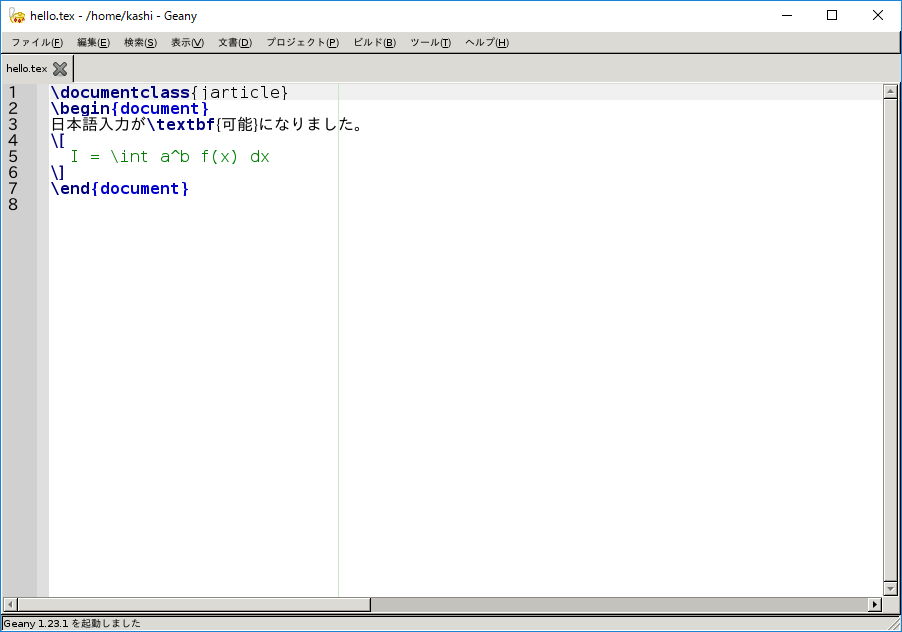
自分はvimで十分ですが、もう少し普通のエディタを使いたいなら、
sudo apt install geanyあたりはいかがでしょうか。
ま、windows側のお気に入りのエディタを使えば済むことではありますが。
vmwareなどの仮想化ソフトを使うよりずっと軽いのが嬉しいです。windowsとの分業がしやすいのも大きな利点かと。次はsshdなどサーバ系のソフトをいろいろ試してみたいと思います。
追記
上で書いたかな漢字変換サーバとlxterminalの起動を自動化するなら、例えばhome directoryの.bashrcの末尾に
if [ $SHLVL -eq 1 ]; then
if DISPLAY=localhost:0.0 xset q > /dev/null 2>&1 ; then
DISPLAY=localhost:0.0 UIM_CANDWIN_PROG=uim-candwin-gtk uim-xim &
DISPLAY=localhost:0.0 XMODIFIERS="@im=uim" GTK_IM_MODULE=uim QT_IM_MODULE=uim lxterminal &
fi
fi
のように書けばいいでしょう。最初に起動されたbashで、なおかつXが利用可能なら、かな漢字変換サーバとlxterminalを起動します。次のwindows10の大型アップデートでubuntu 16.04になるとか日本語入力も普通に出来るようになるとか噂が聞こえてくるので、そのときにはここに書いたことの大半は無意味になってしまうかもしれません。
この記事は、次のページを参考に書きました。
- Bash on Ubuntu on Windowsメモ
- Bash on Ubuntu on Windowsをインストールしてみよう!
- Bash on Ubuntu on Windows とX Windowの組み合わせで日本語表示と日本語入力
- 俺の Bash on Windows10 環境
- Bash on Ubuntu on WindowsでTensorFlowを使うためのメモ
- Cygwin絶対殺すマン ~物理のオタクがWindows Subsystem for Linuxで数値計算できるようになるまで~
















